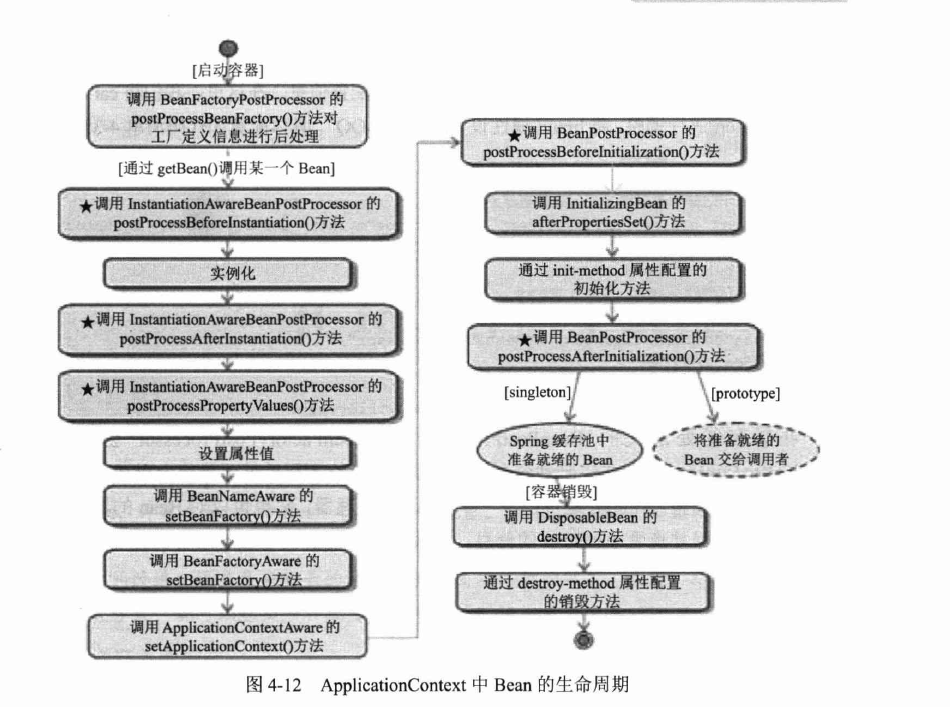
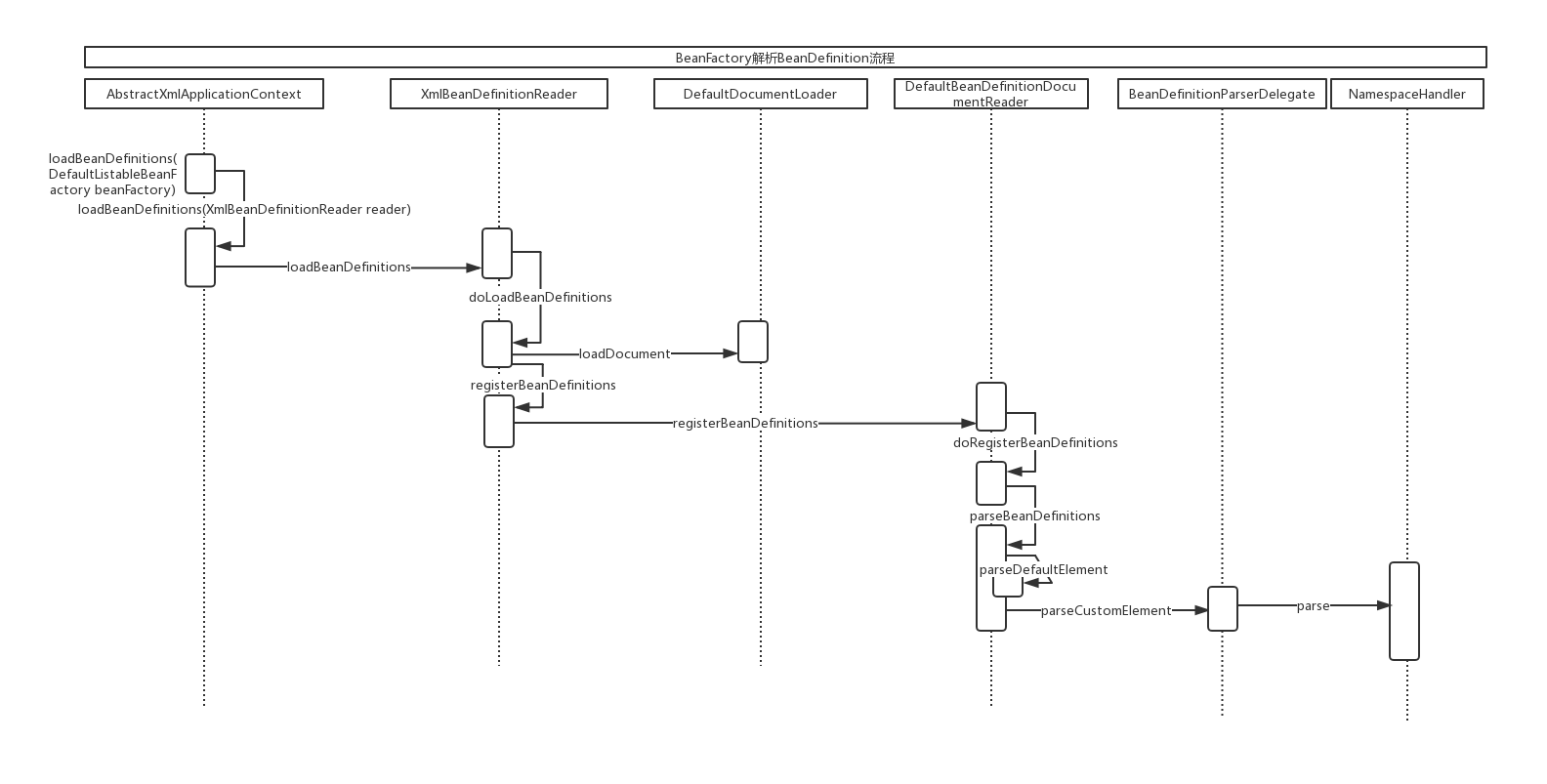
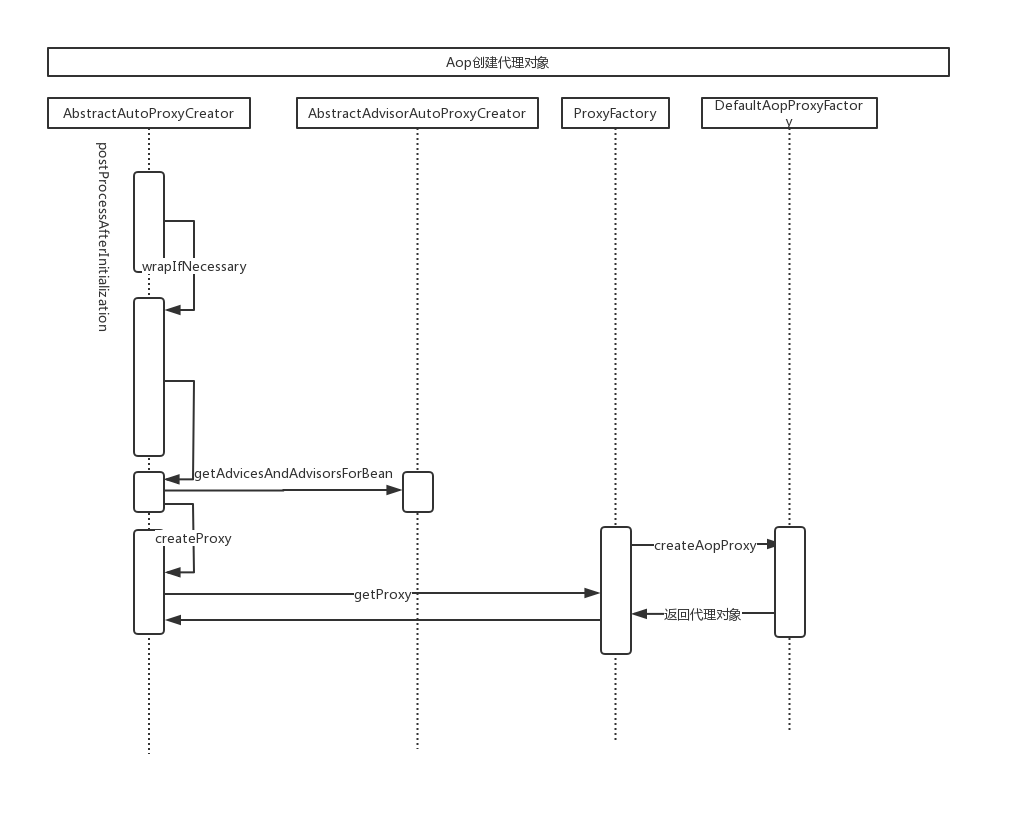
Spring Boot可以轻松创建独立的,生产级的基于Spring的应用程序。使用“约定大于配置”的思想,SpringBoot通过对Spring平台和第三方库进行了一些约定的配置,使大多数Spring Boot应用程序只需要很少的Spring配置。
特点
- 为所有Spring开发提供更快更广泛的入门体验。
- 提供大型项目(例如嵌入式服务器,安全性,度量标准,运行状况检查和外部化配置)通用的一系列非功能性功能
- 绝对没有代码生成并且对XML也没有配置要求
Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件。maven通过配置pom.xml配置文件来配置构建项目的方法和依赖。
a)compile 编译 例如spring-core
b)test 测试
c)provided编译 例如 servlet
d)runtime运行时 例如JDBC驱动实现
e)system 本地一些jar 例如短信jar
依赖冲突时的仲裁方法
Maven的生命周期是为了对所有的构建过程进行了抽象了,便于统一。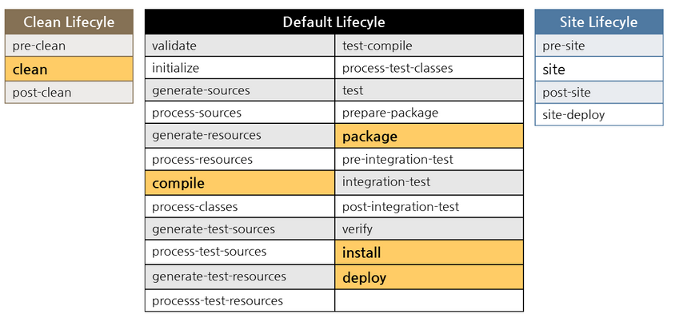
clean(清理)
cleanup(清理所有)
此生命周期旨在给工程做清理工作,它主要包含以下阶段:
pre-clean - 执行项目清理前所需要的工作。
clean - 清理上一次build项目生成的文件。
post-clean - 执行完成项目清理所需的工作.
default(默认)
validate - 验证项目是否正确且所有必要的信息都可用。
initialize - 初始化构建工作,如:设置参数,创建目录等。
generate-sources - 为包含在编译范围内的代码生成源代码.
process-sources - 处理源代码, 如过滤值.
generate-resources -
process-resources - 复制并处理资源文件,至目标目录,准备打包。
compile - 编译项目中的源代码.
process-classes - 为编译生成的文件做后期工作, 例如做Java类的字节码增强.
generate-test-sources - 为编译内容生成测试源代码.
process-test-sources - 处理测试源代码。
generate-test-resources -
process-test-resources - 复制并处理资源文件,至目标测试目录。
test-compile - 将需测试源代码编译到路径。一般来说,是编译/src/test/java目录下的java文件至目标输出的测试classpath目录中。
process-test-classes -
test - 使用合适的单元测试框架运行测试。这些测试代码不会被打包或部署。
prepare-package -
package - 接受编译好的代码,打包成可发布的格式,如 JAR 。
pre-integration-test -
integration-test - 按需求将发布包部署到运行环境。
post-integration-test -
verify -
install -将包安装到本地仓库,给其他本地引用提供依赖。
deploy -完成集成和发布工作,将最终包复制到远程仓库以便分享给其他开发人员。
site(站点)
pre-site - 执行一些生成项目站点前的准备工作。
site - 生成项目站点的文档。
post-site - 执行需完成站点生成的工作,如站点部署的准备工作。
site-deploy - 向制定的web服务器部署站点生成文件。
a)
b)extends AbstractMojo
Channel EventLoopGroup EventLoop
ChannelHandler ChannelContext ChannelPipeline
BootStrap ServerBootStrap
ByteBuf
使用
分配
访问
类型
unpool
pool
heap
direct
ByteBufHolder
ByteBuf的释放 引用计数法
原文:https://segmentfault.com/a/1190000008315137#articleHeader11 是根据logback官网翻译来的
Logback是log4j项目的改进版本。Logback的体系结构足够通用,以便在不同情况下应用。目前,logback分为三个模块:logback-core,logback-classic和logback-access。logback-core 是其它模块的基础设施,其它模块基于它构建,显然,logback-core 提供了一些关键的通用机制。logback-classic 的地位和作用等同于 Log4J,它也被认为是 Log4J 的一个改进版,并且它实现了简单日志门面 SLF4J;而 logback-access 主要作为一个与 Servlet 容器交互的模块,比如说 tomcat 或者 jetty,提供一些与 HTTP 访问相关的功能
实际上,这两个日志框架都出自同一个开发者之手,Logback 相对于 Log4J 有更多的优点
同样的代码路径,Logback 执行更快
更充分的测试
原生实现了 SLF4J API(Log4J 还需要有一个中间转换层)
内容更丰富的文档
支持 XML 或者 Groovy 方式配置
配置文件自动热加载
从 IO 错误中优雅恢复
自动删除日志归档
自动压缩日志成为归档文件
支持 Prudent 模式,使多个 JVM 进程能记录同一个日志文件
支持配置文件中加入条件判断来适应不同的环境
更强大的过滤器
支持 SiftingAppender(可筛选 Appender)
异常栈信息带有包信息
maven依赖包
1 | <!-- 日志--> |
logback.xml配置文件
1 | <?xml version="1.0" encoding="UTF-8"?> |
获取Logger,打印日志
这里会使用配置的root的appender[STDOUT],把日志打印到控制台。
1 | Logger logger = LoggerFactory.getLogger("chapters.introduction.HelloWorld1"); |
LogBack基于三个主要的类:Logger,Appender,Layout.三种类型的组件协同工作,使开发人员能够根据消息类型和级别记录消息,在运行时控制这些消息的格式以及日志的位置。
为了可以控制哪些信息需要输出,哪些信息不需要输出,logback 中引进了一个 分层 概念。每个 logger 都有一个 name,这个 name 的格式与 Java 语言中的包名格式相同。这也是前面的例子中直接把一个 class 对象传进 LoggerFactory.getLogger() 方法作为参数的原因。
logger 的 name 格式决定了多个 logger 能够组成一个树状的结构,为了维护这个分层的树状结构,每个 logger 都被绑定到一个 logger 上下文中,这个上下文负责厘清各个 logger 之间的关系。
例如, 命名为 io.beansoft 的 logger,是命名为 io.beansoft.logback 的 logger 的父亲,是命名为 io.beansoft.logback.demo 的 logger 的祖先。
在 logger 上下文中,有一个 root logger,作为所有 logger 的祖先,这是 logback 内部维护的一个 logger,并非开发者自定义的 logger。
可通过以下方式获得这个 logger :1
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);
同样,通过 logger 的 name,就能获得对应的其它 logger 实例。
Logger 这个接口主要定义的方法有:1
2
3
4
5
6
7
8
9
10package org.slf4j;
public interface Logger {
// Printing methods:
public void trace(String message);
public void debug(String message);
public void info(String message);
public void warn(String message);
public void error(String message);
}
logger 有日志打印级别,可以为一个 logger 指定它的日志打印级别。
如果不为一个 logger 指定打印级别,那么它将继承离他最近的一个有指定打印级别的祖先的打印级别。这里有一个容易混淆想不清楚的地方,如果 logger 先找它的父亲,而它的父亲没有指定打印级别,那么它会立即忽略它的父亲,往上继续寻找它爷爷,直到它找到 root logger。因此,也能看出来,要使用 logback, 必须为 root logger 指定日志打印级别。
日志打印级别从低级到高级排序的顺序是:
TRACE < DEBUG < INFO < WARN < ERROR
如果一个 logger 允许打印一条具有某个日志级别的信息,那么它也必须允许打印具有比这个日志级别更高级别的信息,而不允许打印具有比这个日志级别更低级别的信息。
举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41package io.beansoft.logback.demo.universal;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import ch.qos.logback.classic.Level;
/**
*
*
* @author beanlam
* @date 2017年2月10日 上午12:20:33
* @version 1.0
*
*/
public class LogLevelDemo {
public static void main(String[] args) {
//这里强制类型转换时为了能设置 logger 的 Level
ch.qos.logback.classic.Logger logger =
(ch.qos.logback.classic.Logger) LoggerFactory.getLogger("com.foo");
logger.setLevel(Level.INFO);
Logger barlogger = LoggerFactory.getLogger("com.foo.Bar");
// 这个语句能打印,因为 WARN > INFO
logger.warn("can be printed because WARN > INFO");
// 这个语句不能打印,因为 DEBUG < INFO.
logger.debug("can not be printed because DEBUG < INFO");
// barlogger 是 logger 的一个子 logger
// 它继承了 logger 的级别 INFO
// 以下语句能打印,因为 INFO >= INFO
barlogger.info("can be printed because INFO >= INFO");
// 以下语句不能打印,因为 DEBUG < INFO
barlogger.debug("can not be printed because DEBUG < INFO");
}
}
打印结果是:1
200:27:19.251 [main] WARN com.foo - can be printed because WARN > INFO
00:27:19.255 [main] INFO com.foo.Bar - can be printed because INFO >= INFO
### 获取 logger
在 logback 中,每个 logger 都是一个单例,调用 LoggerFactory.getLogger 方法时,如果传入的 logger name 相同,获取到的 logger 都是同一个实例。
在为 logger 命名时,用类的全限定类名作为 logger name 是最好的策略,这样能够追踪到每一条日志消息的来源。
在 logback 的世界中,日志信息不仅仅可以打印至 console,也可以打印至文件,甚至输出到网络流中,日志打印的目的地由 Appender 来决定,不同的 Appender 能将日志信息打印到不同的目的地去。
Appender 是绑定在 logger 上的,同时,一个 logger 可以绑定多个 Appender,意味着一条信息可以同时打印到不同的目的地去。例如,常见的做法是,日志信息既输出到控制台,同时也记录到日志文件中,这就需要为 logger 绑定两个不同的 logger。
Appender 是绑定在 logger 上的,而 logger 又有继承关系,因此一个 logger 打印信息时的目的地 Appender 需要参考它的父亲和祖先。在 logback 中,默认情况下,如果一个 logger 打印一条信息,那么这条信息首先会打印至它自己的 Appender,然后打印至它的父亲和父亲以上的祖先的 Appender,但如果它的父亲设置了 additivity = false,那么这个 logger 除了打印至它自己的 Appender 外,只会打印至其父亲的 Appender,因为它的父亲的 additivity 属性置为了 false,开始变得忘祖忘宗了,所以这个 logger 只认它父亲的 Appender;此外,对于这个 logger 的父亲来说,如果父亲的 logger 打印一条信息,那么它只会打印至自己的 Appender中(如果有的话),因为父亲已经忘记了爷爷及爷爷以上的那些父辈了。
打印的日志除了有打印的目的地外,还有日志信息的展示格式。在 logback 中,用 Layout 来代表日志打印格式。比如说,PatternLayout 能够识别以下这条格式:
%-4relative [%thread] %-5level %logger{32} - %msg%n
然后打印出来的格式效果是:
176 [main] DEBUG manual.architecture.HelloWorld2 - Hello world.
上面这个格式的第一个字段代表从程序启动开始后经过的毫秒数,第二个字段代表打印出这条日志的线程名字,第三个字段代表日志信息的日志打印级别,第四个字段代表 logger name,第五个字段是日志信息,第六个字段仅仅是代表一个换行符。
经常能看到打印日志的时候,使用以下这种方式打印日志: 1
logger.debug("the message is " + msg + " from " + somebody);
这种打印日志的方式有个缺点,就是无论日志级别是什么,程序总要先执行 “the message is “ + msg + “ from “ + somebody 这段字符串的拼接操作。当 logger 设置的日志级别为比 DEBUG 级别更高级别时,DEBUG 级别的信息不回被打印出来的,显然,字符串拼接的操作是不必要的,当要拼接的字符串很大时,这无疑会带来很大的性能白白损耗。
于是,一种改进的打印日志方式被人们发现了:1
2
3if(logger.isDebugEnabled()) {
logger.debug("the message is " + msg + " from " + somebody);
}
这样的方式确实能避免字符串拼接的不必要损耗,但这也不是最好的方法,当日志级别为 DEBUG 时,那么打印这行消息,需要判断两次日志级别。一次是logger.isDebugEnabled(),另一次是 logger.debug() 方法内部也会做的判断。这样也会带来一点点效率问题,如果能找到更好的方法,谁愿意无视白白消耗的效率。
有一种更好的方法,那就是提供占位符的方式,以参数化的方式打印日志,例如上述的语句,可以是这样的写法:1
logger.debug("the message {} is from {}", msg, somebody);
这样的方式,避免了字符串拼接,也避免了多一次日志级别的判断。
当应用程序发起一个记录日志的请求,例如 info() 时,logback 的内部运行流程如下所示
获得过滤器链条
检查日志级别以决定是否继续打印
创建一个 LoggingEvent 对象
调用 Appenders
进行日志信息格式化
发送 LoggingEvent 到对应的目的地
关于日志系统,人们讨论得最多的是性能问题,即使是小型的应用程序,也有可能输出大量的日志。打印日志中的不当处理,会引发各种性能问题,例如太多的日志记录请求可能使磁盘 IO 成为性能瓶颈,从而影响到应用程序的正常运行。在合适的时候记录日志、以更好的方式发起日志请求、以及合理设置日志级别方面,都有可能造成性能问题。
关于性能问题,以下几个方面需要了解
建议使用占位符的方式参数化记录日志
logback 内部机制保证 logger 在记录日志时,不必每一次都去遍历它的父辈以获得关于日志级别、Appender 的信息.(additivity=”false”)
在 logback 中,将日志信息格式化,以及输出到目的地,是最损耗性能的操作
logback 提供的配置方式有以下几种:
编程式配置
xml 格式
groovy 格式
logback 在启动时,根据以下步骤寻找配置文件:
在 classpath 中寻找 logback-test.xml文件
如果找不到 logback-test.xml,则在 classpath 中寻找 logback.groovy 文件
如果找不到 logback.groovy,则在 classpath 中寻找 logback.xml文件
如果上述的文件都找不到,则 logback 会使用 JDK 的 SPI 机制查找 META-INF/services/ch.qos.logback.classic.spi.Configurator 中的 logback 配置实现类,这个实现类必须实现 Configuration 接口,使用它的实现来进行配置
如果上述操作都不成功,logback 就会使用它自带的 BasicConfigurator 来配置,并将日志输出到 console
logback-test.xml 一般用来在测试代码中打日志,如果是 maven 项目,一般把 logback-test.xml 放在 src/test/resources 目录下。maven 打包的时候也不会把这个文件打进 jar 包里。
logback 启动的时候解析配置文件大概需要 100 毫秒的时间,如果希望更快启动,可以采用 SPI 的方式。
前面有提到默认的配置,由 BasicConfiguator 类配置而成,这个类的配置可以用如下的配置文件来表示:1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>
如果 logback 在启动时,解析配置文件时,出现了需要警告的信息或者错误信息,那 logback 会自动先打印出自身的状态信息。
如果希望正常情况下也打印出状态信息,则可以使用之前提到的方式,在代码里显式地调用使其输出:1
2
3
4
5
6
7public static void main(String[] args) {
// assume SLF4J is bound to logback in the current environment
LoggerContext lc = (LoggerContext) LoggerFactory.getILoggerFactory();
// print logback's internal status
StatusPrinter.print(lc);
...
}
也可以在配置文件中,指定 configuration 的 debug 属性为 true1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration debug="true">
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type ch.qos.logback.classic.encoder.PatternLayoutEncoder
by default -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>
还可以指定一个 Listener:1
2
3<configuration>
<statusListener class="ch.qos.logback.core.status.OnConsoleStatusListener" />
</configuration>
这个Listener不打印内部状态1
<statusListener class="ch.qos.logback.core.status.NopStatusListener"/>
重置默认的配置文件位置
设置 logback.configurationFile 系统变量,可以通过 -D 参数设置,所指定的文件名必须以 .xml 或者 .groovy 作为文件后缀,否则 logback 会忽略这些文件。
要使配置文件自动重载,需要把 scan 属性设置为 true,默认情况下每分钟才会扫描一次,可以指定扫描间隔:1
2
3<configuration scan="true" scanPeriod="30 seconds" >
...
</configuration>
注意扫描间隔要加上单位,可用的单位是 milliseconds,seconds,minutes 和 hours。如果只指定了数字,但没有指定单位,这默认单位为 milliseconds。
在 logback 内部,当设置 scan 属性为 true 后,一个叫做 ReconfigureOnChangeFilter 的过滤器就会被牵扯进来,它负责判断是否到了该扫描的时候,以及是否该重新加载配置。Logger 的任何一个打印日志的方法被调用时,都会触发这个过滤器,所以关于这个过滤器的自身的性能问题,变得十分重要。logback 目前采用这样一种机制,当 logger 的调用次数到达一定次数后,才真正让过滤器去做它要做的事情,这个次数默认是 16,而 logback 会在运行时根据调用的频繁度来动态调整这个数目。
输出异常栈时也打印出 jar 包的信息
这个属性默认是关闭,可通过以下方式开启:1
2
3<configuration packagingData="true">
...
</configuration>
也可以通过 LoggerContext 的 setPackagingDataEnabled(boolean) 方法来开启
LoggerContext lc = (LoggerContext) LoggerFactory.getILoggerFactory();
lc.setPackagingDataEnabled(true);
Joran 是 logback 使用的一个配置加载库,如果想要重新实现 logback 的配置机制,可以直接调用这个类 JoranConfigurator 来实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65package chapters.configuration;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import ch.qos.logback.classic.LoggerContext;
import ch.qos.logback.classic.joran.JoranConfigurator;
import ch.qos.logback.core.joran.spi.JoranException;
import ch.qos.logback.core.util.StatusPrinter;
public class MyApp3 {
final static Logger logger = LoggerFactory.getLogger(MyApp3.class);
public static void main(String[] args) {
// assume SLF4J is bound to logback in the current environment
LoggerContext context = (LoggerContext) LoggerFactory.getILoggerFactory();
try {
JoranConfigurator configurator = new JoranConfigurator();
configurator.setContext(context);
// Call context.reset() to clear any previous configuration, e.g. default
// configuration. For multi-step configuration, omit calling context.reset().
context.reset();
configurator.doConfigure(args[0]);
} catch (JoranException je) {
// StatusPrinter will handle this
}
StatusPrinter.printInCaseOfErrorsOrWarnings(context);
logger.info("Entering application.");
Foo foo = new Foo();
foo.doIt();
logger.info("Exiting application.");
}
}
```
## 配置文件格式
### 配置文件的基本结构
根节点是 configuration,可包含0个或多个 appender,0个或多个 logger,最多一个 root。
### 配置 logger 节点
在配置文件中,logger 的配置在<logger> 标签中配置,<logger> 标签只有一个属性是一定要的,那就是 name,除了 name 属性,还有 level 属性,additivity 属性可以配置,不过它们是可选的。
level 的取值可以是 TRACE, DEBUG, INFO, WARN, ERROR, ALL, OFF, INHERITED, NULL, 其中 INHERITED 和 NULL 的作用是一样的,并不是不打印任何日志,而是强制这个 logger 必须从其父辈继承一个日志级别。
additivity 的取值是一个布尔值,true 或者 false。
<logger> 标签下只有一种元素,那就是 <appender-ref>,可以有0个或多个,意味着绑定到这个 logger 上的 Appender。
### 配置 root 节点
<root> 标签和 <logger> 标签的配置类似,只不过 <root> 标签只允许一个属性,那就是 level 属性,并且它的取值范围只能取 TRACE, DEBUG, INFO, WARN, ERROR, ALL, OFF。
<root> 标签下允许有0个或者多个 <appender-ref>。
### 配置 appender 节点
<appender> 标签有两个必须填的属性,分别是 name 和 class,class 用来指定具体的实现类。<appender> 标签下可以包含至多一个 <layout>,0个或多个 <encoder>,0个或多个 <filter>,除了这些标签外,<appender> 下可以包含一些类似于 JavaBean 的配置标签。
<layout> 包含了一个必须填写的属性 class,用来指定具体的实现类,不过,如果该实现类的类型是 PatternLayout 时,那么可以不用填写。<layout> 也和 <appender> 一样,可以包含类似于 JavaBean 的配置标签。
<encoder> 标签包含一个必须填写的属性 class,用来指定具体的实现类,如果该类的类型是 PatternLayoutEncoder ,那么 class 属性可以不填。
如果想要往一个 logger 上绑定 appender,则使用以下方式:
```xml
<logger name="HELLO" level="debug">
<appender-ref ref="FILE" />
<appender-ref ref="STDOUT" />
</logger>
1 | <configuration> |
在 logback 中,支持以 ${varName} 来引用变量
定义变量
可以直接在 logback.xml 中定义变量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<property name="USER_HOME" value="/home/sebastien" />
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${USER_HOME}/myApp.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="FILE" />
</root>
</configuration>
也可以通过大D参数来定义1
java -DUSER_HOME="/home/sebastien" MyApp2
也可以通过外部文件来定义1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<property file="src/main/java/chapters/configuration/variables1.properties" />
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${USER_HOME}/myApp.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="FILE" />
</root>
</configuration>
外部文件也支持 classpath 中的文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<property resource="resource1.properties" />
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${USER_HOME}/myApp.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="FILE" />
</root>
</configuration>
外部文件的格式是 key-value 型。
USER_HOME=/home/sebastien
变量有三个作用域
local
local 作用域在配置文件内有效
context
context 作用域的有效范围延伸至 logger context
system
system 作用域的范围最广,整个 JVM 内都有效。
logback 在替换变量时,首先搜索 local 变量,然后搜索 context,然后搜索 system。
如何为变量指定 scope ?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<property scope="context" name="nodeId" value="firstNode" />
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/opt/${nodeId}/myApp.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="FILE" />
</root>
</configuration>
在引用一个变量时,如果该变量未定义,那么可以为其指定默认值,做法是:1
${aName:-golden}
需要使用 1
2
3
4
5
6
7
8
9
10<configuration>
<define name="rootLevel" class="a.class.implementing.PropertyDefiner">
<shape>round</shape>
<color>brown</color>
<size>24</size>
</define>
<root level="${rootLevel}"/>
</configuration>
使用 1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<insertFromJNDI env-entry-name="java:comp/env/appName" as="appName" />
<contextName>${appName}</contextName>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d ${CONTEXT_NAME} %level %msg %logger{50}%n</pattern>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
条件化处理还需要加入janino库,用于解析表达式1
2
3
4
5<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
<version>2.6.1</version>
</dependency>
logback 允许在配置文件中定义条件语句,以决定配置的不同行为,具体语法格式如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45 <!-- if-then form -->
<if condition="some conditional expression">
<then>
...
</then>
</if>
<!-- if-then-else form -->
<if condition="some conditional expression">
<then>
...
</then>
<else>
...
</else>
</if>
``
示例:
```xml
<configuration debug="true">
<if condition='property("HOSTNAME").contains("torino")'>
<then>
<appender name="CON" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d %-5level %logger{35} - %msg %n</pattern>
</encoder>
</appender>
<root>
<appender-ref ref="CON" />
</root>
</then>
</if>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${randomOutputDir}/conditional.log</file>
<encoder>
<pattern>%d %-5level %logger{35} - %msg %n</pattern>
</encoder>
</appender>
<root level="ERROR">
<appender-ref ref="FILE" />
</root>
</configuration>
可以使用 1
2
3
4
5
6
7
8<configuration>
<include file="src/main/java/chapters/configuration/includedConfig.xml"/>
<root level="DEBUG">
<appender-ref ref="includedConsole" />
</root>
</configuration>
被包含的文件必须有以下格式:1
2
3
4
5
6
7<included>
<appender name="includedConsole" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>"%d - %m%n"</pattern>
</encoder>
</appender>
</included>
支持从多种源头包含
从文件中包含1
<include file="src/main/java/chapters/configuration/includedConfig.xml"/>
从 classpath 中包含1
<include resource="includedConfig.xml"/>
从 URL 中包含1
<include url="http://some.host.com/includedConfig.xml"/>
如果包含不成功,那么 logback 会打印出一条警告信息,如果不希望 logback 抱怨,只需这样做:1
<include optional="true" ..../>
添加一个 Context Listener
LoggerContextListener 接口的实例能监听 logger context 上发生的事件,比如说日志级别的变化,添加的方式如下所示:1
2
3
4<configuration debug="true">
<contextListener class="ch.qos.logback.classic.jul.LevelChangePropagator"/>
....
</configuration>
fastjson是阿里提供的json操作的开源项目。特点是api简单,效率高。
fastjson的大部分操作都可以通过JSON对象静态调用。
这样就可以将object转成json字符串1
String jsonStr=JSON.toJSONString(object);
带有日期格式转化1
2public static String toJSONStringWithDateFormat(Object object, String dateFormat,
SerializerFeature... features) {
toJSONString方法还有很多重载方法,SerializeFilter可以用来过滤不需要转json字符串的字段。SerializerFeature配置序列化的特征。1
public static String toJSONString(Object object, SerializeFilter[] filters, SerializerFeature... features)
SerializeConfig 序列化时的配置,可以添加特点类型自定义的序列化。1
2
3
4public static String toJSONString(Object object, //
SerializeConfig config, //
SerializeFilter filter, //
SerializerFeature... features)
将字符串转成对象可以通过JSON.parseObject方法,该方法有许多重载,可以定制反序列化。
如果没有加需要转成的类型的化,就会把对象转化为JSONObject1
public static JSONObject parseObject(String text)
传入转化的class就会转成改对象1
public static <T> T parseObject(String text, Class<T> clazz)
通过TypeReference构造转化类型1
2
3
4public static <T> T parseObject(String text, TypeReference<T> type, Feature... features)
//将json转为带泛型的map对象
Map<String,String> map=JSON.parseObject(msg,new TypeReference<Map<String,String>>(String.class,String.class){},null);
ParserConfig可以用于添加特定类型的自定义反序列化,ParseProcess用于处理json字符串中存在,对象中没有的额外字段1
2public static <T> T parseObject(String input, Type clazz, ParserConfig config, ParseProcess processor,
int featureValues, Feature... features)
反序列化数组可以通过parseArray,也可以用parseObject1
public static <T> List<T> parseArray(String text, Class<T> clazz)
| 名称 | 含义 |
|---|---|
| QuoteFieldNames | 输出key时是否使用双引号,默认为true |
| UseSingleQuotes | 使用单引号而不是双引号,默认为false |
| WriteMapNullValue | 是否输出值为null的字段,默认为false |
| WriteEnumUsingToString | Enum输出name()或者original,默认为false |
| UseISO8601DateFormat | Date使用ISO8601格式输出,默认为false |
| WriteNullListAsEmpty | List字段如果为null,输出为[],而非null |
| WriteNullStringAsEmpty | 字符类型字段如果为null,输出为”“,而非null |
| WriteNullNumberAsZero | 数值字段如果为null,输出为0,而非null |
| WriteNullBooleanAsFalse | Boolean字段如果为null,输出为false,而非null |
| SkipTransientField | 如果是true,类中的Get方法对应的Field是transient,序列化时将会被忽略。默认为true |
| SortField | 按字段名称排序后输出。默认为false |
| WriteTabAsSpecial | 把\t做转义输出,默认为false 不推荐 |
| PrettyFormat | 结果是否格式化,默认为false |
| WriteClassName | 序列化时写入类型信息,默认为false。反序列化是需用到 |
| DisableCircularReferenceDetect | 消除对同一对象循环引用的问题,默认为false |
| WriteSlashAsSpecial | 对斜杠’/’进行转义 |
| BrowserCompatible | 将中文都会序列化为\uXXXX格式,字节数会多一些,但是能兼容IE 6,默认为false |
| WriteDateUseDateFormat | 全局修改日期格式,默认为false。JSON.DEFFAULT_DATE_FORMAT = “yyyy-MM-dd”;JSON.toJSONString(obj, SerializerFeature.WriteDateUseDateFormat); |
| DisableCheckSpecialChar | 一个对象的字符串属性中如果有特殊字符如双引号,将会在转成json时带有反斜杠转移符。如果不需要转义,可以使用这个属性。默认为false |
| NotWriteRootClassName | 含义 |
| BeanToArray | 将对象转为array输出 |
| WriteNonStringKeyAsString | 含义 |
| NotWriteDefaultValue | 含义 |
| BrowserSecure | 含义 |
| IgnoreNonFieldGetter | 含义 |
| WriteEnumUsingName | 枚举类型通过名字转化 |
fastjson默认提供的对枚举类型的反序列化的方式有两种
但是如果需要通过自定义的值反序列化成枚举,就需要自定义反序列化器。
如下面枚举,我想通过EnumValue接口返回的value值进行反序列化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16interface EnumValue{
int value();
}
enum TestEnum implements EnumValue{
TEST1(1),
TEST2(2),
;
private int value;
TestEnum(int value){
this.value=value;
}
public int value() {
return value;
}
}
1 | class Bean{ |
通过下面代码直接序列化,int类型的值会自动用ordinal,ordinal从0开始 ,TestEnum枚举有2个,ordinal值从0-1,这里会发生ArrayIndexOutOfBoundsException1
2
3String jsonStr = "{\"id\":1,\"testEnum\":2}";
Bean bean = JSON.parseObject(jsonStr, Bean.class);
System.out.println(bean);
解决方法:
1 | class EnumValueDeserializer implements ObjectDeserializer { |
注册有三种方法
1 | String jsonStr = "{\"id\":1,\"testEnum\":2}"; |
1 | (deserializer = EnumValueDeserializer.class) |
#### 复写ParserConfig,替换掉默认的枚举反序列化器,这种方式是全局的,对所有枚举起作用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 class MyParserConfig extends ParserConfig{
public ObjectDeserializer getDeserializer(Class<?> clazz, Type type) {
ObjectDeserializer derializer;
if (clazz.isEnum()) {
Class<?> deserClass = null;
JSONType jsonType = clazz.getAnnotation(JSONType.class);
if (jsonType != null) {
deserClass = jsonType.deserializer();
try {
derializer = (ObjectDeserializer) deserClass.newInstance();
this.putDeserializer(type,derializer);
return derializer;
} catch (Throwable error) {
// skip
}
}
//这里替换了原来的反序列化器。
derializer = new EnumValueDeserializer();
return derializer;
}
return super.getDeserializer(clazz, type);
}
1 | String jsonStr = "{\"id\":1,\"testEnum\":2}"; |
1 | Test obj = JSON.parseObject(msg, new TypeReference<Test>() { |
但是对于对象中带有get方法的list字段,fastjson的处理:
通过get方法获取list或map,如果是null不会处理。
以下带来。com.alibaba.fastjson.parser.deserializer.FieldDeserializer类 setValue方法片段。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23else if (Map.class.isAssignableFrom(method.getReturnType())) {
Map map = (Map) method.invoke(object);
if (map != null) {
if (map == Collections.emptyMap()
|| map.getClass().getName().startsWith("java.util.Collections$Unmodifiable")) {
// skip
return;
}
map.putAll((Map) value);
}
} else {
Collection collection = (Collection) method.invoke(object);
if (collection != null && value != null) {
if (collection == Collections.emptySet()
|| collection == Collections.emptyList()
|| collection.getClass().getName().startsWith("java.util.Collections$Unmodifiable")) {
// skip
return;
}
collection.clear();
collection.addAll((Collection) value);
}
}
所以以下例子反序列化出来的ids属性为null。1
2
3
4
5
6
7
8
9
10
11
12
13public class Test {
private int id;
private List<Integer> ids;
public int getId() {
return id;
}
public List<Integer> getIds() {
return ids;
}
}
1 | String msg="[" + |
解决方法
1 | //ParserConfig 构造函数中将fieldbased设置为true,开启只基于字段进行反序列化。 |
设置了fieldBased,反序列化处理来ids就有值了
Twitter-Snowflake算法,为了满足每秒产生上万条不重复id并且保证一定的顺序的产生。
雪花算法生成id结构
|____|__|___|
1 41位 时间戳 10位机器id 12位序列号
最高位不用,加起来64位,可以用一个long表示。
41位时间戳表示毫秒,每毫秒的序列号都从0开始加,12bit序列号最大可以4095
1 | //开始生成的时间戳,用当前时间戳-twepoch作为雪花算法的时间戳 |
面向切面编程(AOP)通过提供另一种关于程序结构的思考来补充面向对象编程(OOP)。OOP中模块化的关键单元是类,而在AOP中,模块化单元是切面。切面能够实现跨越多种类型和对象的关注点(例如事务管理,日志处理,访问控制)的模块化。
简单点说就是:在一个方法的前后植入逻辑,这个方法就是一个切入点。原理是通过动态代理生成代理类,Spring中给我们使用的是他生成的代理类。
切面:跨越多个类别的关注点的模块化。事务管理是企业Java应用程序中横切关注点的一个很好的例子。在Spring AOP中,方面是通过使用常规类(基于模式的方法)或使用@Aspect注释(@AspectJ样式)注释的常规类来实现的 。
连接点:程序执行期间的一个点,例如执行的方法或处理异常。在Spring AOP中,连接点始终表示执行的方法(目标对象的目标方法)。
通知:拦截到连接点之前或之后处理的一段逻辑,这段逻辑一般是切面中的方法
切入点:匹配连接点的定义(例如,执行具有特定名称的方法),Spring中用切入点表达式定义。由切入点表达式匹配的连接点的概念是AOP的核心,而Spring默认使用AspectJ切入点表达式语言。
引介:可以让程序员对现有的类添加新的接口,并确定该接口方法的实现
目标对象:由一个或多个切面切入的对象。由于Spring AOP是使用运行时代理实现的,因此该对象始终是代理对象。目标对象中的被代理的方法就是连接点
AOP代理:由AOP框架创建的对象,代理对象是将切面中的通知根据切入点表达式织入到目标对象的方法中。在Spring Framework中,AOP代理是JDK动态代理或CGLIB代理。
编织:将方面与其他应用程序类型或对象链接以创建通知对象。这可以在编译时(例如使用AspectJ编译器),加载时间或在运行时完成。与其他纯Java AOP框架一样,Spring AOP在运行时执行编织。
Spring AOP包含以下类型的通知:
前置通知:在连接点之前运行但无法阻止执行流程进入连接点的通知(除非它引发异常)。
后置通知:在连接点正常完成后运行的通知(例如,如果方法返回而不抛出异常)。
异常通知:如果方法通过抛出异常退出,则执行通知。
最终通知:无论连接点退出的方式(正常或异常返回),都要执行通知。
围绕通知:围绕连接点的通知,例如方法调用。围绕通知可以在方法调用之前和之后执行自定义行为。它还负责选择是继续执行连接点还是通过返回自己的返回值或抛出异常来快速通知的方法执行。
Spring AOP默认使用AOP代理的标准JDK动态代理,如果目标类没有接口的话就会采用CGLIB.
配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd">
<context:component-scan base-package="com.qworldr">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>
<!--开启切面注解支持 -->
<aop:aspectj-autoproxy/>
</beans>
切面类1
2
3
4
5
6
7
8
9
10
11
12
13
public class Aspectj {
//切入点,切入TestService类的无参方法
("execution(* com.qworldr.service.TestService.*())")
public void pointcut(){};
//前置通知,使用pintcut方法上配置的切入点
("pointcut()")
public void before(){
System.out.println("test执行前");
}
}
目标类1
2
3
4
5
6
7
8
public class TestService {
//连接点
public void test(){
System.out.println("执行test");
}
}
测试1
2
3
4
5
6
7
8
9
10(locations = "classpath:applicationContext.xml")
public class Test01 {
private TestService testService;
public void test(){
testService.test();
}
}
运行结果1
2test执行前
执行test
从运行结果可以看出,前置通知再连接点之前执行。
上面例子就是通过注解方式实现的AOP。
注解方式除了依赖Spring-aop,还依赖下面两个包1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjrt</artifactId>
<version>1.9.1</version>
</dependency>
1 |
|
1 | <aop:aspectj-autoproxy/> |
1 | /** |
切面类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class XMLAspectj {
public void before(){
System.out.println("前置通知 test执行前");
}
public void afterReturn(JoinPoint joinPoint,Object val){
System.out.println("后置通知:"+val);
}
public void afterThrowing(JoinPoint joinPoint,Throwable ex){
System.out.println("异常:"+ex);
}
public void after(){
System.out.println("最终通知 xml test执行后");
}
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
System.out.println("环绕通知 test执行前");
Object proceed = joinPoint.proceed();
System.out.println("环绕通知 xml test执行后");
return proceed;
}
}
xml配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22<bean id="aspect" class="com.qworldr.aspectj.XMLAspectj"></bean>
<aop:config>
<aop:aspect id="aspect" ref="aspect">
<aop:pointcut id="pointcut" expression="execution(* com.qworldr.service.TestService.*())"/>
<aop:before method="before" pointcut-ref="pointcut"></aop:before>
<!-- 后置通知,通知方法可以有两个参数
JoinPoint point 可以获得目标方法和参数值
Object val 这里的名字要和returning=”val”中保持一致,指的是方法的返回值。
-->
<aop:after-returning method="afterReturn" pointcut-ref="pointcut" returning="val"></aop:after-returning>
<!-- 异常通知,通知方法可以有两个参数
JoinPoint point 可以获得目标方法和参数值
Throwable ex 这里的名字要和throwing="ex" 中保持一致,指的是方法的抛出的异常。
-->
<aop:after-throwing method="afterThrowing" pointcut-ref="pointcut" throwing="ex"></aop:after-throwing>
<aop:after method="after" pointcut-ref="pointcut" ></aop:after>
<!-- 环绕通知,通知方法可以有1个参数
ProceedingJoinPoin point 可以控制连接点的执行,ProceedingJoinPoint的proceed方法相当于invoke方法,调用目标类的目标方法
-->
<aop:around method="around" pointcut-ref="pointcut" ></aop:around>
</aop:aspect>
</aop:config>
通过切入点表达式匹配感兴趣的连接点,控制通知何时执行。
execution:用于匹配方法执行的连接点;
within:用于匹配指定类型内的方法执行
this:用于匹配当前AOP代理对象类型的执行方法
target:用于匹配当前目标对象类型的执行方法
args:用于匹配当前执行的方法传入的参数为指定类型的执行方法
@within:用于匹配所以持有指定注解类型内的方法
@target:用于匹配当前目标对象类型的执行方法,其中目标对象持有指定的注解
@args:用于匹配当前执行的方法传入的参数持有指定注解的执行
@annotation:用于匹配当前执行方法持有指定注解的方法;
execution(modifiers-pattern? ret-type-pattern declaring-type-pattern?name-pattern(param-pattern)
throws-pattern?)
modifiers-pattern? 权限匹配符,不必须
ret-type-pattern 放回值类型, 可用 表示任任何返回值
declaring-type-pattern? 路径,不必须,可用 表示任意文件夹,.. 表示任意一级或多级路径。
name-pattern 方法名 , 表示任务名字,例子:set 表示以set开头的
(param-pattern) 方法参数 ()匹配一个不带参数的方法,而(..)匹配任何数量(零个或多个)参数
throws-pattern? 异常类型,不必须
*:匹配任何数量字符;
..:匹配任何数量字符的重复,如在类型模式中匹配任何数量子包;而在方法参数模式中匹配任何数量参数。
+:匹配指定类型的子类型;仅能作为后缀放在类型模式后边。
切入点直接可以通过 && ,|| ,! 进行运算。
com.xyz.service包或其子包中的参数是java.io.Serializable的连接点。
1
within(com.xyz.service..*)&&args(java.io.Serializable)
com.xyz.service包或其子包的任何连接点或者参数是java.io.Serializable的连接点。
1
within(com.xyz.service..*)||args(java.io.Serializable)
不在com.xyz.service包中的任何连接点。
1
!within(com.xyz.service..*)
com.xyz.service包下的任意方法
1
execution(* com.xyz.service..*.*(..))
com.xyz.service包或其子包中的任何连接点
1
within(com.xyz.service..*)
代理实现AccountService接口的任何连接点
1
this(com.xyz.service.AccountService)
目标对象实现AccountService接口的任何连接点
1
target(com.xyz.service.AccountService)
运行方法参数列表是(java.io.Serializable)的连接点
1
args(java.io.Serializable)
目标对象具有该注解的连接点
1
(org.springframework.transaction.annotation.Transactional)
目标对象具有该注解的连接点
1
(org.springframework.transaction.annotation.Transactional)
目标方法具有该注解的连接点
1
(org.springframework.transaction.annotation.Transactional)
当多个通知需要在同一个连接点(执行方法)执行时,切面之间的优先级是通过Orde注解或者让bean实现Ordered接口来确定的。
可以让程序员对现有的类添加新的接口,并确定该接口方法的实现
1
2
3
4
5
6
7
public class Aspectj {
//给TestService类添加接口Intorduction,Introduction接口的方法默认实现是IntroductionImpl
(value = "com.qworldr.service.TestService",defaultImpl = IntroductionImpl.class)
public Introduction introduction;
}
测试
TestService可以强转成为Introduction对象运行。1
2
3
4
5
6
7
8
private TestService testService;
public void test(){
testService.test();
Introduction testService = (Introduction) this.testService;
System.out.println(testService.introduction());
}