jdk8的ConcurrentHashMap改动非常大。放弃了之前segment锁,改用cas+synchronized来实现同步。
常量含义
1 | /** |
重要变量
table
用来存放Node节点数据的数组,默认为null,默认大小为16,每次扩容时大小总是2的幂次方;下文的table都是指这个属性
nextTable
扩容时新表,数组为table的两倍,扩容完毕会赋给table
baseCount
map的大小
sizeCtl
控制标识符,用来控制table初始化和扩容操作的,在不同的地方有不同的用途,其值也不同,所代表的含义也不同
负数代表正在进行初始化或扩容操作
-1代表正在初始化
-N 表示有N-1个线程正在进行扩容操作
正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小
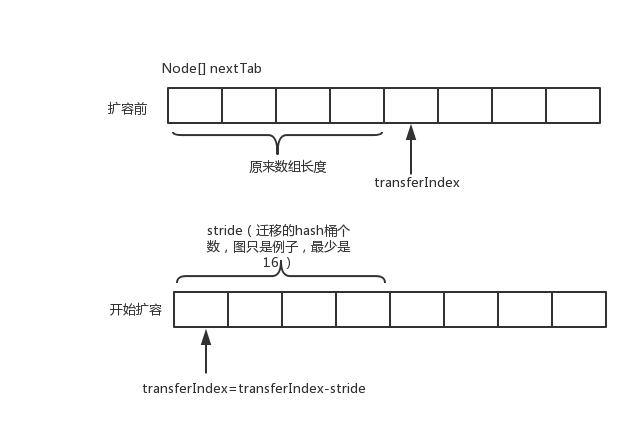
transferIndex
表示已经分配给扩容线程的table数组索引位置。主要用来协调多个线程扩容。transferIndex初始化是指向table.length。当开始扩容时,首先要将transferIndex右移(以cas的方式修改 transferIndex=transferIndex-stride(要迁移hash桶的个数)),获取迁移任务。每个扩容线程都会通过for循环+CAS的方式设置transferIndex,因此可以确保多线程扩容的并发安全。
内部类
Node
节点,保存key-value的数据结构;value字段和next用volatile修饰,保障可见性。读数据时不需要加锁。可以看到Node不支持setValue。修改值直接node.val=xxx修改。1
2
3
4
5
6
7
8
9
10static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
}
TreeNode
红黑树节点1
2
3
4
5
6
7
8static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
...
}
TreeBin
用于封装红黑树,持有红黑树根节点的引用。包含一个读写锁用于写线程等待读线程完成,再tree重新构造之前。
1 | static final class TreeBin<K,V> extends Node<K,V> { |
ForwardingNode
一个特殊的Node节点,hash值为-1(MOVED常量),其中存储nextTable的引用。只有table发生扩容的时候,ForwardingNode才会发挥作用,作为一个占位符放在table中表示当前节点为null或则已经被移动1
2
3
4
5
6 final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
....
主要方法解析
put方法
put方法调用了putVal方法。1
2
3public V put(K key, V value) {
return putVal(key, value, false);
}
putVal方法关键代码解析
计算hash值
spread方法通过高16位异或低16位来散列。因为后面计算table坐标时是采用 hash&(length-1)的公式来计算。
也就是说只会保留低位,这样大大加大了出现hash冲突的概率。这里用高位^低位,增加低位的随机性,减少hash冲突的次数。1
2
3static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}tab==null时,先进行table的初始化。
1
2if (tab == null || (n = tab.length) == 0)
tab = initTable();通过 (table.length-1)&hash算出脚标i,如果table脚标i的元素为null。说明不存在hash冲突。将key,val封装成Node,通过cas直接设置进table,跳出循环。cas失败说明其他线程修改了该脚标节点,重新开始循环。
1
2
3
4
5else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}节点f是table中脚标为i,如果该节点hash==MOVE,说明该节点是ForwardingNode且其他线程正在对这个map进行扩容。当前线程也协助扩容。
1
2else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);不是前面几种情况的话,就是说明存在hash冲突。将新节点加入以f为根节点的链表或红黑树。这里只需要锁住根节点,相比以前的分段锁粒度更小。红黑树用TreeBin对象封装,hash=-2。hash大于0即是链表。节点加入链表会记录一个链表长度binCount,如果binCount>=TREEIFY_THRESHOLD,链表会向红黑树转化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44else{
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}addCount方法分两部分,一、更新baseCount,二、判断是否扩容
1
addCount(1L, binCount);
1 | private final void addCount(long x, int check) {} |
扩容transfer
transfer是可以多线程进行的。通过给每个线程分配迁移(将table中的hash桶迁移到新的nextTab中)的hash桶,每个线程最少迁移16个hash桶,用transferIndex来同步。一个map扩容,要迁移的hash桶是原来的table长度。分配时从后面的分配起。从下图看出,每个线程分配的hash桶脚标范围是transferIndex-stride(线程迁移的hash桶个数)到transferIndex-1。分配完一个线程后,通过cas将transferIndex设置为transferIndex-stride。
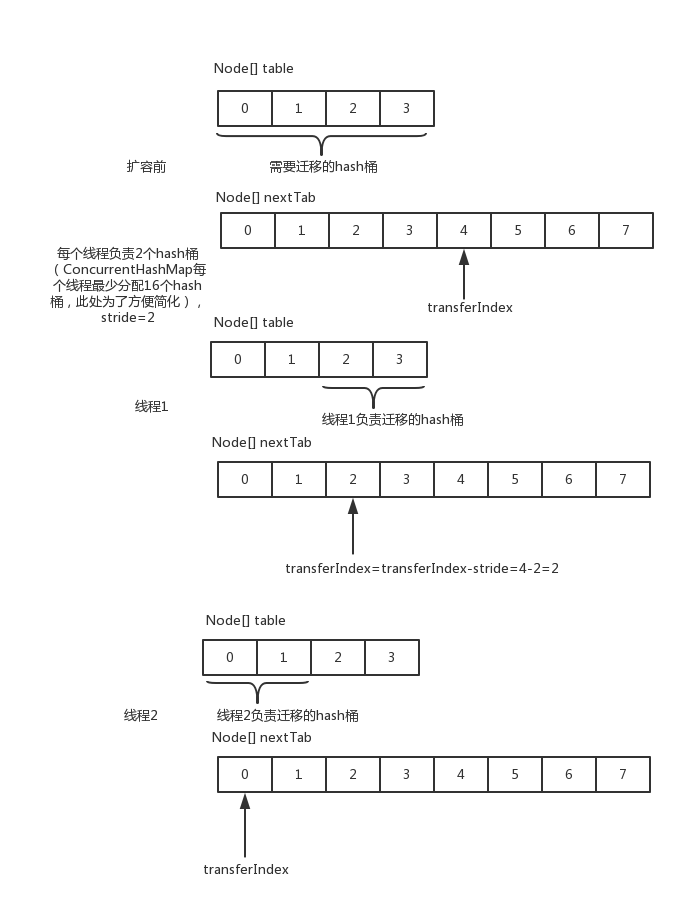
线程迁移的hash桶个数最少是16,图中为了方便没画这么多。
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
get方法
get方法不需要加锁。因为Node的val是volatile修饰的,所以其他线程的修改对当前线程是可见的。
- 先获取key对应的脚标i,table[i]==null,返回null。table[i]节点的key是否和key是否相等。相等则返回val。
- table[i].hash<0,则说明节点是TreeBin或者ForwardingNode节点,通过该节点的find方法找出key对应的节点。
- 不是以上情况则是链表,遍历链表找到key对应的节点值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}